Python rq 轻量级的任务队列 rq是类celery的一个轻量级的任务队列,但是任务存储后端没有celery丰富,只支持redis,也依赖于redis,不过简单好用。
安装 Queue 队列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 from rq import Queuefrom redis import Redisdef foo (name) : print(f"hello {name} " ) host = "xxx.xxx.x.xxx" port = 6379 db = 0 redis_conn = Reids(host=host, port=port, db=db) q = Queue("myqueue" , connection=redis_conn) job = q.enqueue(foo, "world" , result_ttl=600 , ttl=30 , fail_ttl=600 , job_timeou=600 ) print(len(q)) print(q.job_ids) print(q.jobs) job = q.fetch_job("job_id" ) q.empty() q.delete(delete_jobs=True )
Job 任务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 from rq import get_current_jobfrom rq.decorators import jobhost = "xxx.xxx.x.xxx" port = 6379 db = 0 redis_conn = Reids(host=host, port=port, db=db) @job("myqueue", connection=redis_conn) def foo (name) : return f"hello, {name} " job = foo.delay("world" ) print(job.id) print(job.get_status()) print(job.func_name) print(job.args) print(job.kwargs) print(job.result) print(job.exc_info) def bar () : job = get_current_job() job.meta["name" ] = "world" job.save_meta() return "Bar" def job1 () : return "job1 ok" def job2 () : return "job2 ok" job_1 = q.enqueue(job1) q.enqueue(job2, depends_on=job_1) from rq import Workerdef test () : print(1 /0 ) test_job = q.enqueue(test) worker = Worker([queue]) worker.work(burst=True ) print(test_job.is_failed) registry = queue.failed_job_registry assert len(registry) == 1 registry.requeue(test_job) assert len(registry) == 0 assert queue.count == 1
Worker 工作者 1 2 // 启动一个工作者 $ rq worker queue_name
rq工作者每次只处理一个任务,如果要同时执行多个任务,可以开启多个工作者
1 2 3 4 // 以Burst模式启动 // 默认启动方式在所有任务完成时将会阻塞等待新任务到来 // burst参数可以在所有任务完成时退出当前工作者 $ rq -burst worker queue_name
其他参数
--url or -u: redis连接地址 (e.g rq worker --url redis://:[email protected] :1234/9 or rq worker --url unix:///var/run/redis/redis.sock)
--path or -P: 支持多个导入路径 (e.g rq worker --path foo --path bar)
--config or -c: RQ配置文件模块路径
--results-ttl: 任务结果存储秒数(默认为500秒)
--worker-class or -w: RQ Worker类 (e.g rq worker --worker-class ‘foo.bar.MyWorker’)
--job-class or -j: RQ Job类
--queue-class: RQ Queue类
--connection-class: redis连接类(默认为redis.StrictRedis)
--log-format: worker打印日志格式(默认为’%(asctime)s %(message)s’)
--date-format: worker打印日志日期格式(默认为’%H:%M:%S’)
--disable-job-desc-logging: 关闭任务描述日志
--max-jobs: 最大执行任务数
性能优化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import sysfrom rq import Connection, Workerimport preload_libwith Connection(): qs = sys.argv[1 :] or ["default" ] w = Worker(qs) w.work()
检索工作者信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from redis import Redisfrom rq import Queue, Workerredis_conn = Redis() workers = Worker.all(connection=redis_conn) queue = Queue('queue_name' ) workers = Worker.all(queue=queue) print(Worker.count(connection=redis_conn)) print(Worker.count(queue=queue)) worker = workers[0 ] print(worker.name) print(worker.hostname) print(worker.pid) print(worker.queues) print(worker.state) print(worker.current_job) print(worker.last_heartbeat) print(worker.birth_date) print(worker.successful_job_count) print(worker.failed_job_count) print(worker.total_working_time)
使用配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 REDIS_URL = 'redis://localhost:6379/1' QUEUES = ['high' , 'default' , 'low' ] SENTRY_DSN = 'sync+http://public:[email protected] /1'
无工作者模式 1 2 3 4 5 6 7 8 9 10 11 12 from redis import Redisfrom rq import Queue, Workerdef foo () : print("foo" ) redis_conn = Redis() q = Queue("queue_name" , is_async=False , connection=redis_conn) job = q.enqueue(foo) print(job.result)
Scheduler 调度器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from datetime import datetime, timedeltafrom rq import Queuefrom rq.registry import ScheduledJobRegistryfrom redis import Redisdef foo () : print("hi" ) q = Queue(name="default" , connection=Redis()) job = q.enqueue(datetime(2020 , 6 , 24 , 9 , 57 ), foo) job = q.enqueue(timedelta(seconds=10 ), foo) print(job in q) registry = ScheduledJobRegistry(queue=queue) print(job in registry)
运行调度器
1 $ rq worker --with-scheduler
通过代码运行
1 2 3 4 5 6 7 8 from rq import Worker, Queuefrom redis import Redisredis = Redis() queue = Queue(connection=redis) worker = Worker(queues=[queue], connection=redis) worker.work(with_scheduler=True )
Connections 连接 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from rq import use_connectionuse_connection() from rq import Queuefrom redis import Redisconn1 = Redis('localhost' , 6379 ) conn2 = Redis('remote.host.org' , 9836 ) q1 = Queue('foo' , connection=conn1) q2 = Queue('bar' , connection=conn2) import unittestfrom rq import push_connection, pop_connectionclass MyTest (unittest.TestCase) : def setUp (self) : push_connection(Redis()) def tearDown (self) : pop_connection() def test_foo (self) : q = Queue()
Job Registries 任务注册表 每个队列都会维护一组任务注册表
StartedJobRegistry 保存当前正在执行的任务。任务在执行前添加,完成(成功或失败)后被删除。
FinishedJobRegistry 保存成功执行的任务。
FailedJobRegistry 保存完成但失败的任务。
DeferredJobRegistry 保存延迟任务(依赖任务)。
ScheduledJobRegistry 保存计划任务。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 from redis import Redisfrom rq import Queuefrom rq.registry import StartedJobRegistrydef foo () : print("foo" ) redis = Redis() queue = Queue("queue_name" , connection=redis) job = queue.enqueue(foo) registry1 = StartedJobRegistry(queue=queue) registry2 = StartedJobRegistry(name="queue_name" , connection=redis) print(registry1.get_queue()) print(registry1.count) print(registry1.get_job_ids()) print(job in registry1) print(job.id in registry1) print(queue.started_job_registry) print(queue.deferred_job_registry) print(queue.finished_job_registry) print(queue.failed_job_registry) print(queue.scheduled_job_registry) from rq.registry import FailedJobRegistryfaild_registry = FailedJobRegistry(queue=queue) for job_id in faild_registry.get_job_ids(): faild_registry.remove(job_id)
Serialize 序列化 1 2 3 4 5 6 7 8 9 10 11 import jsonfrom rq import Job, Queue, Workerjob = Job(connection=connection, serializer=json) queue = Queue(connection=connection, serializer=json) worker = Worker(queue, serializer=json)
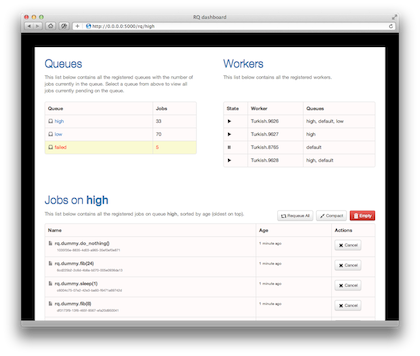
Monitoring 监控 使用RQ dashboard RQ dashboard
1 2 $ pip install rq-dashboard $ rq-dashboard
使用CLI工具 rq info 命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 $ rq info -u redis://127.0.0.1:6379/1 cost | 0 mailbox | 0 2 queues, 0 jobs total 8e006dec6d0146f392ab624af6cbb738 (root 21767): idle cost a2a1ecde7c934e3ba6751bffc499e4f4 (root 44482): idle mailbox 2 workers, 2 queues Updated: 2020-06-24 10:58:51.994777 ``` 指定队列名称 ```bash $ rq info cost -u redis://127.0.0.1:6379/1 cost | 0 1 queues, 0 jobs total 8e006dec6d0146f392ab624af6cbb738 (root 21767): idle cost 1 workers, 1 queues Updated: 2020-06-24 10:59:06.786965
按队列分组
1 2 3 4 5 6 7 8 9 10 $ rq info -R -u redis://127.0.0.1:6379/1 cost | 0 mailbox | 0 2 queues, 0 jobs total cost: 8e006dec6d0146f392ab624af6cbb738 (idle) mailbox: a2a1ecde7c934e3ba6751bffc499e4f4 (idle) 2 workers, 2 queues Updated: 2020-06-24 11:02:58.784870
间隔轮询(默认rq info命令打印一次信息就会退出,加上interval参数将会每隔N秒刷新一次屏幕)
Exceptions 异常处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 from redis import Redisfrom rq import Queue, Workerfrom exception_handlers import foo_handler, bar_handlerdef my_handler (job, exc_type, exc_value, traceback) : pass q = Queue(connection=Redis()) w = Worker([q], exception_handlers=[foo_handler, bar_handler, my_handler])
单元测试 👉
Flask中使用RQ添加上下文 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from redis import Redisfrom rq import Queue, Jobfrom flask.cli import ScriptInfoclass FlaskRqJob (Job) : ''' 自定义Job类 添加flask上下文 需要设置FLASK_APP环境变量 ''' def __init__ (self, *args, **kwargs) : super().__init__(*args, **kwargs) self.script_info = ScriptInfo() def perform (self) : if current_app: app = current_app else : app = self.script_info.load_app() with app.app_context(): return super().perform() q = Queue(name="queue_name" , connection=Redis(), job_class=FlaskRqJob)
运行worker时也要指定相应job class,且需要指定flask app路径(设置FLASK_APP环境变量)
1 2 $ export FLASK_APP=app:app $ rq worker -j package.module.FlaskRqJob